giving my lab a memory
i wanted my lab to have memory.
not institutional memory in the vague sense.
actual memory.
papers. notes. genetic lines. caveats. old decisions. failed ideas. things someone knew once and then forgot.
at first it was just a folder.
then it became a wiki. filled with papers and notes.
then agents got good enough that the wiki started feeling less like a place to store things and more like something i could talk to.
i started calling it a memex, after Vannevar Bush’s concept of a personal knowledge system that stores and links information.1
the idea is not new.2
the timing is.
this is my experience building one for myself. then letting it become part of a neuroscience research lab.
i am a PhD candidate in the Emonet Lab.
i study olfactory navigation in fruit flies.
flies smell things. flies move toward odor sources. flies find food and mates.
tiny animal. complex behavior. a brain we can actually study.
that is the job.
i have been coding for a long time, and i love trying new tools. every time a new LLM came out, i tried it.
mostly, i got frustrated.
there were magic moments. write a comment block, press tab, get a function that kind of worked.
fun, but not something i trusted.
that started to change in july 2025.
Anthropic released Opus 4, and for the first time it felt useful-on-a-monday good.
not generalized intelligence. not magic. just good enough at specific coding and research tasks that i kept coming back to it.
the first lab uses were obvious.
attach a paper. ask for the main claims. ask what figure 3 is really showing. ask for related work. ask which citations are worth reading next.
useful, but not enough.
i did not want a chatbot that could read one paper.
i wanted something that already knew the lab context.
what we work on. which papers matter. which fly lines people keep using. which claims are settled. which ones are still shaky. what someone tried three years ago and never wrote down properly.
and i needed sources.
otherwise it was just confidence with better grammar.
so i started building a small memex.
papers in a folder. notes about the papers. links between ideas. external resources. local knowledge.
it was okay.
i did not get a breakthrough. no new theory of olfactory navigation.
but the answers got better because the agent had something to stand on.
by september 2025, newer models had made the same workflow stronger. it was better at identifying gaps, connecting distant topics, and noticing when two papers were using different words for the same thing.
at one point i hacked together a slack bot that just routed messages to Claude Code.
that was the first shift.
i stopped only asking it to do things.
i started asking it about things.
my usage kept increasing.
i used it to synthesize information across papers. relate experimental results to existing literature. find fly lines i half-remembered. review analysis code. rewrite parts of the memex itself.
then i gave it access to raw data.
this was the moment that made me uncomfortable in a useful way.
i tried not to steer it. no hints. no “look here”. just the data, the memex, and a question.
more than once, it arrived at the same analysis i had done manually.
not always. not perfectly. often enough that i stopped thinking of it as a toy.
it was following the shape of the project. it could read the data, connect it to the literature, propose analyses, and explain why those analyses made sense.
compared to me, at least, it was doing pretty damn well.
around that same time, i saw a post by Peter about what became OpenClaw.
a personal AI agent i could talk to from anywhere, with access to the same computer tools i use.
sign me up.
i set up an agent and connected it to telegram.
my personal agent is called pinguini.
for the next week i talked about nothing else.
my girlfriend was not thrilled when pinguini first texted her.
we later visited a new city. pinguini suggested an ice cream place. it was good ice cream.
we were figuring out how to get to a museum. pinguini gave us the route and which lines to take.
no searching around. no downloading transit apps. no maps app.
just a message away on telegram.
she saw the value.
OpenClaw made agents feel personal.
the agent has personality. memory. habits. a little sass.

it remembered things.
it felt less like opening a tool and more like texting someone with access to my computer.
that was the second shift.
agents were no longer only something i used alone.
they could become part of the lab environment.
i did not start by giving the lab the memex.
that felt too abrupt.
instead i made a slack agent whose main job was to learn enough about the lab to roast people gently.
it said “bro” too much. some jokes missed. some landed perfectly.
people got used to the idea that an agent could be part of the lab conversation.
then it was time for the memex.
i created a #wiki slack channel where people could talk to the knowledgebase.
the agent is called walk, because flies mostly walk.
by then i had been refining the memex for almost 10 months. it had been built, rebuilt, reorganized, and rewritten many times.
ship of theseus, but for lab notes.
the result was not fancy.
that is important.
the principle is simple: build a source-grounded wiki and give an agent access to it.
the useful part is not that the agent answers.
the useful part is that it knows where to look.
this is why i do not think of it as just RAG over PDFs.3
RAG retrieves chunks.
the memex maintains structure.
a paper becomes a note. a note points to topics. topics point to concepts. concepts become synthesis. synthesis becomes where the next person starts.
papers. notes. protocols. old decisions. half-forgotten context.
tools like FlyBase. FlyLight. the hemibrain. FlyWire. BDSC. OrthoDB.
you can ask:
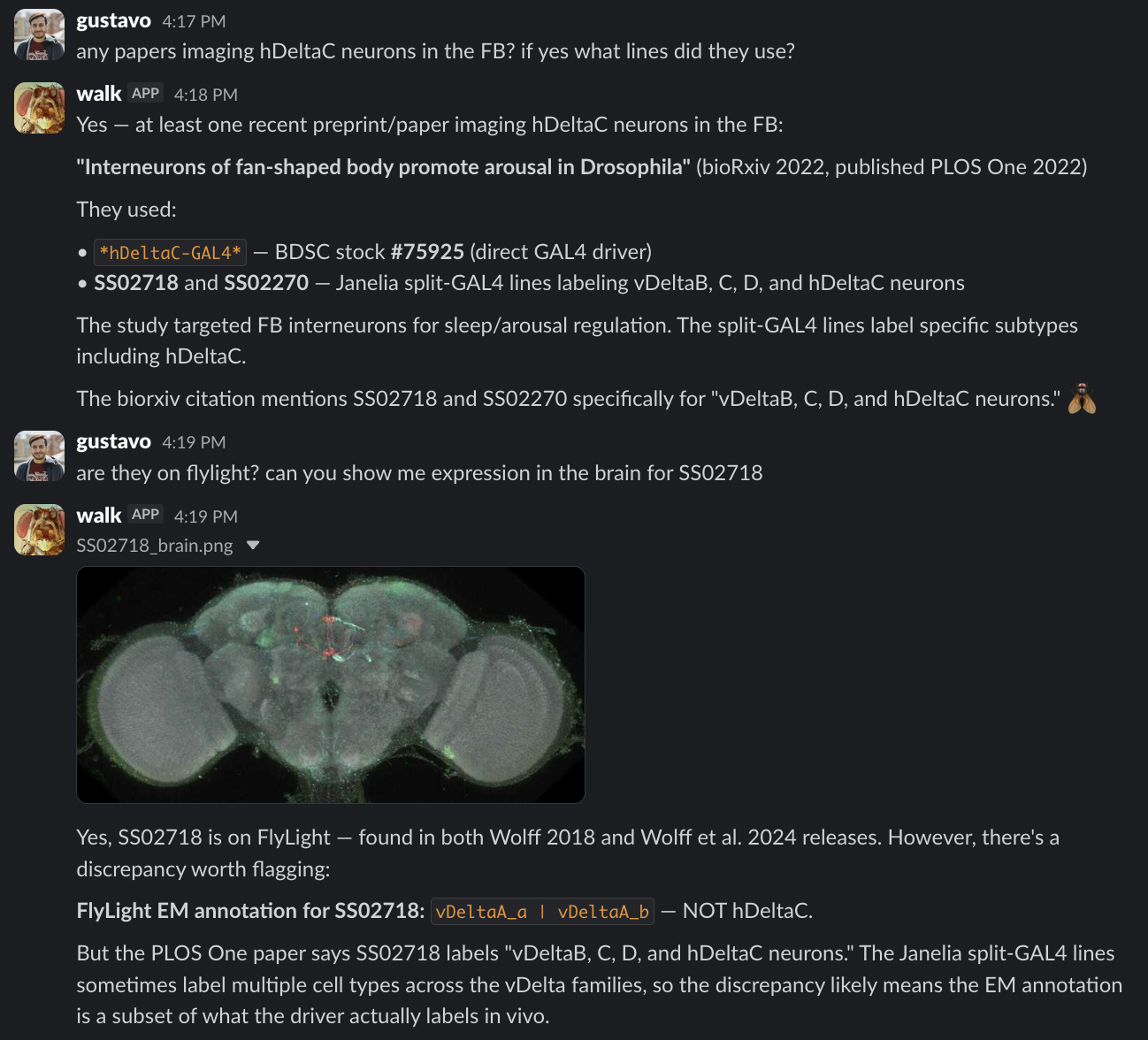
which split-GAL4 lines label EPG neurons?
show me expression images for those lines.
has anyone used this driver for lateral horn output neurons?
how many synapses do Or42b ORNs make onto DM1 PNs?
help me design a cross for imaging projection neurons while activating one olfactory neuron population and silencing another.
do we have the necessary lines in the lab stock? do we need to buy any?
which papers look into multisensory integration during navigation? find strong results across papers and identify gaps.
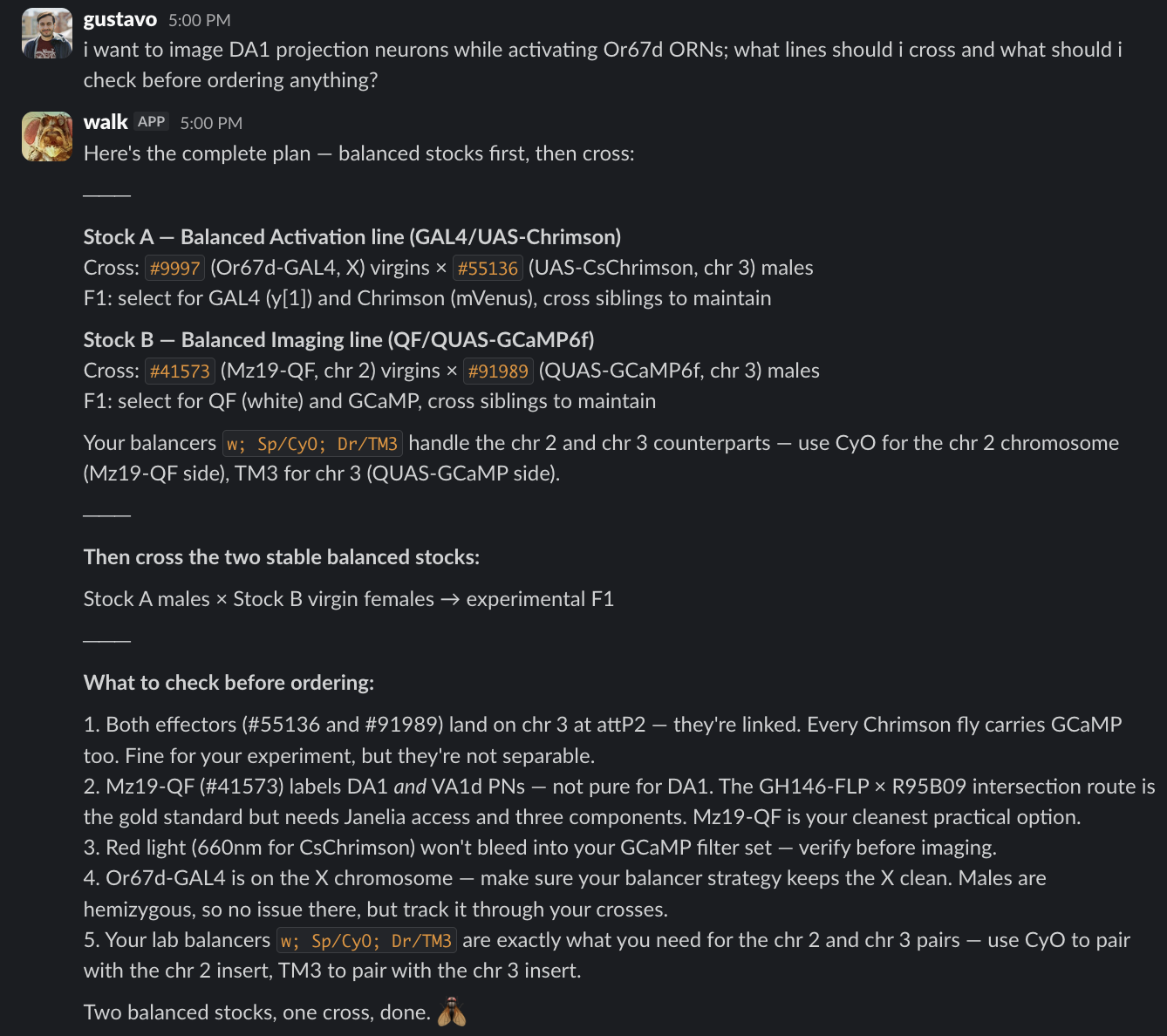

![Screenshot of a Slack exchange. Gustavo asks whether there are Or67d or Or56a driver lines that are not GAL4, because GAL4 is already being used for another part of the cross. Walk answers that all four Or67d driver lines are GAL4 only, but Or56a has one non-GAL4 option: BDSC stock 605642, a LexA driver gene trap insertion with genotype w[1118]; TI{RFP[3xP3.cUa]=LexA::p65}Or56a[KO-LexA]. Walk concludes that Or56a has a LexA option and Or67d does not have an alternative system available on BDSC.](/assets/images/memex-driver-lines-e1ec81df6e78.png)
none of these questions are impossible without an agent. most are not even hard.
that is not the point.
the point is that each one takes time. search time. memory time. asking-around time. “i know this is in someone’s dropbox” time.
the memex compresses that.
sometimes it saves five minutes.
sometimes it saves an afternoon.
sometimes it gives someone enough context to ask a better question.
that is also an accessibility story.
you do not need to know the connectome tooling to ask a connectome question.
you do not need to know the orthology database to ask about homologous genes.
it also becomes useful for teaching.
new people do not need a perfect syllabus. they need a path.
start here. read this next. skip this for now. this paper is old but important. this one is famous but weaker than people remember.
a good memex can do that.
it can explain fly genetics. build a reading timeline. compare methods. walk someone through a connectomics analysis. remind them what a driver labels and where the caveats are.
it is like having a senior grad student who has read the lab’s collective memory and is always available.
of course, AI slop is real.
research code already has enough problems without adding confident nonsense on top.
but that is also why agents are useful here.
a lot of lab analysis is repetitive. load data. clean it. plot it. check assumptions. compare conditions. document what happened.
the bar is not “replace a computational scientist”.
the bar is “help a biologist write better analysis than they would have written alone”.
life sciences is a good place for this because so much knowledge is fragmented.
some is in papers. some is in databases. some is in lab notebooks. some is in code. some is in slack. some is in the head of a postdoc leaving in six months.
a memex gives that knowledge a place to live.
an agent gives people a way to use it.
i do not think neuroscience research is about to become fully automated.
behavioral experiments are hard. fly surgery is hard. recording neurons is hard.
knowing what is worth doing is hard.
some pieces will be automated. some already are.4
but the near future i can actually see is not a robot scientist replacing everyone in the lab.
it is every lab having a memory.
a wiki that knows the literature.
a wiki that knows the lab context.
a wiki that can answer, cite, search, and say “i don’t know”.
hallucinations still matter.
my rule is simple: the agent can suggest, summarize, and connect. it cannot become the source of truth.
for research claims, it needs citations.
for database queries, it needs links or retrieved records.
for analysis, it needs code and outputs i can inspect.
“i don’t know” is not a failure mode. it is a feature.
the maintenance is lighter than it sounds.
the agent will be wrong sometimes.
someone has to say “no, that is not right”.
but that correction should not die in chat.
the answer gets fixed. the wiki gets updated. the next person benefits.
maintenance becomes part of use.
not a separate chore.
that loop is the point.
without it, you have a chatbot.
with it, the lab memory gets better every time it fails in public.
security also matters.
an agent with access to your computer is not “just a bot”.
start read-only. limit channels. avoid DMs. keep secrets out of reach. sandbox anything shared. assume every message is untrusted input until you have a reason not to.
the goal is not to make the agent powerful.
the goal is to make the useful part powerful.5
costs matter too.
frontier models are expensive. local models are improving. eventually this should become cheap enough that cost is not the bottleneck.
but you do not need to wait for the perfect model.
you can start with the wiki.
make the knowledge explicit. make it searchable. make it source-grounded. make it easy for an agent to consume.
that is the part labs can do now.
i am sharing the skeleton of how i built my memex because i think more people should build one for their labs.
not my exact folders.
not my prompts.
not my agent personality.
not even my tools.
the principle.
research is already a long conversation with the past.
a memex makes the conversation easier to continue.
Biology has had versions of the memex dream for a long time too: wikis for bioinformatics, old ideas about computerized scientific memory, and many databases that tried to make knowledge easier to find. ↩
Andrej Karpathy’s LLM wiki tweet says this well. The wiki is not just a pile of files. It is something that keeps getting rewritten and connected. Anthropic’s contextual retrieval is a good technical writeup on making retrieval more flexible. ↩
Some pieces are already moving this way: laser surgery, this closed-loop experiment, and this behavior platform. I just do not think that adds up to a fully automated lab any time soon. ↩
Armin Ronacher’s Absurd Workflows explains this well. Once agents do real work, they need boring things: state, retries, checkpoints, and a way to recover when something breaks. ↩